LLM Cultural Alignment: Synthetic Data Generation and Cultural Value Alignment in NileChat
Published:
Behind the Paper
NileChat addresses a common problem in low-resource LLM adaptation. Egyptian and Moroccan Arabic are widely spoken, but continued pretraining data in these dialects remains limited. Translating large amounts of English educational content into the target dialect can improve fluency and knowledge transfer. However, translation alone does not ensure that a model captures local heritage, everyday references, or community-specific value patterns. That gap between linguistic adaptation and cultural alignment motivates the NileChat pipeline.
Pipeline summary: The paper combines machine translation of educational content for fluency and knowledge transfer, controlled synthetic data generation for LLM adaptation conditioned on local context, cultural heritage concepts, linguistic expressions, and representative personas, and a retrieval step that queries culturally specific web content. The pipeline is applied to Egyptian and Moroccan Arabic communities.
This work is directly relevant to LLM cultural alignment, cultural bias in LLMs, synthetic data generation for LLMs, and the evaluation of cultural value alignment in LLM systems.
Translation
Educational translation for fluency, coherence, and topical breadth.
Synthetic Generation
Local context documents, heritage concepts, linguistic cues, and representative personas.
Retrieval
Search-and-parse culturally specific web content for local heritage coverage.
Define the community, not just the language label
The paper treats alignment targets as communities rather than abstract language names. “Arabic” is too broad. Even “Egyptian Arabic” or “Moroccan Arabic” is still incomplete unless the intended speech varieties, scripts, references, and value distributions are specified.
This framing is also relevant to discussions of cultural bias in LLMs. If the target community is underspecified, the resulting model may inherit source-language assumptions or dominant-culture defaults instead of local norms.
This framing raises several practical design questions:
- Which forms of speech should feel natural to the model?
- Which local references should be treated as common knowledge rather than niche trivia?
- Which social and moral distinctions matter enough to shape the data?
- Which communities are included, and which are still underrepresented?
This framing changes the unit of design. The task is not only to translate a corpus into another language, but to construct a corpus that reflects how a community talks, remembers, and evaluates.
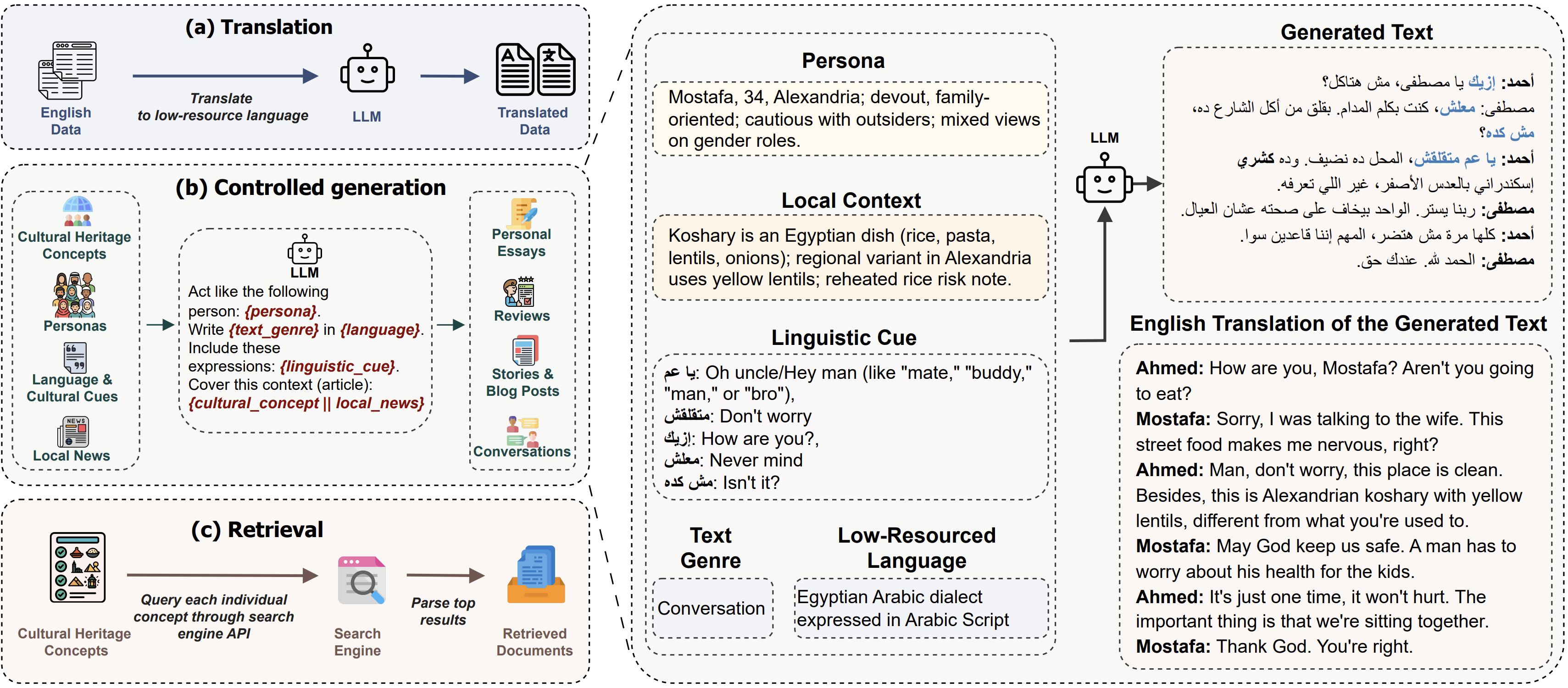
Each data source served a different role
The pipeline assigns distinct responsibilities to three layers rather than expecting a single corpus to satisfy every objective.
1. Translation provided breadth
In the paper, machine translation is the layer for linguistic fluency and coherence. Educational content is translated from English into Egyptian and Moroccan Arabic.
That translated layer was chosen for topical breadth. It covers areas such as education, history, health, medicine, and biology, which helps continued pretraining when native dialectal corpora are limited.
Translated data can still carry source-language cultural biases, so MT improves language coverage and general knowledge without by itself solving cultural heritage or value alignment.
2. Controlled synthetic generation used local context and personas
Controlled synthetic generation is not open-ended prompting. The teacher model is conditioned on four components: local contextual information from local news websites, core cultural heritage concepts extracted from country-specific Wikipedia portals, linguistic and cultural expressions such as proverbs, idioms, TV dialogue, and local terminology, and representative personas derived from World Values Survey responses.
This setup limits open-ended invention. The prompt ties the generated text to realistic documents and a concrete persona profile, and the appendix explicitly instructs the model to rely on the provided context while reflecting the persona’s background.
Prompt Structure In The Paper
Inputs: a persona description, local context text, a cultural concept, and dialect-specific linguistic cues.
Generation task: write a story, personal essay, blog post, review, or conversation in the target dialect rather than Modern Standard Arabic.
- Use the provided context when writing.
- Reflect the persona's cultural background, values, and worldview.
- Incorporate dialectal expressions and local wording supplied in the prompt.
- Keep the output in the target dialect and avoid drifting into MSA.
- Use the persona implicitly instead of restating the persona description.
The pipeline deliberately generates multiple genres: stories, personal essays, blog posts, reviews, and conversations. This variety exposes the model to different discourse patterns rather than one synthetic template repeated at scale.
This is the core synthetic data generation for LLMs component of the pipeline. The paper uses synthetic generation to shape local discourse, persona-grounded language, and culturally specific content rather than relying only on translated corpora.
3. Retrieval added local cultural heritage material
Retrieval in NileChat is also a data-construction step for pretraining, not an inference-time retriever. The system queries a search engine API using predefined cultural concepts that span categories such as food, clothes, landmarks, festivals and celebrations, geography, handicrafts, architecture, fauna, flora, and music.
For each concept, it keeps the top 20 search results and parses the textual content with Trafilatura. This retrieved material adds naturally occurring, culturally specific web text that prompting alone may not provide.
Key point: translation can teach a model how to say things in a target variety, but it cannot by itself teach the model what a community treats as obvious, familiar, or socially legible.
Role of personas
Personas are the mechanism for bringing moral, demographic, and socioeconomic variation into the synthetic data.
A key methodological detail is where they come from. The personas were derived from World Values Survey participant responses, not hand-written stereotypes. Selected survey answers were transformed into textual descriptions and then summarized by an LLM into concise persona profiles that could be plugged into prompts.
The paper generates 1,200 persona descriptions from Egyptian and Moroccan WVS participants. Once those personas were combined with local context, cultural concepts, and linguistic cues, the synthetic data became more closely tied to the target communities than translation alone.
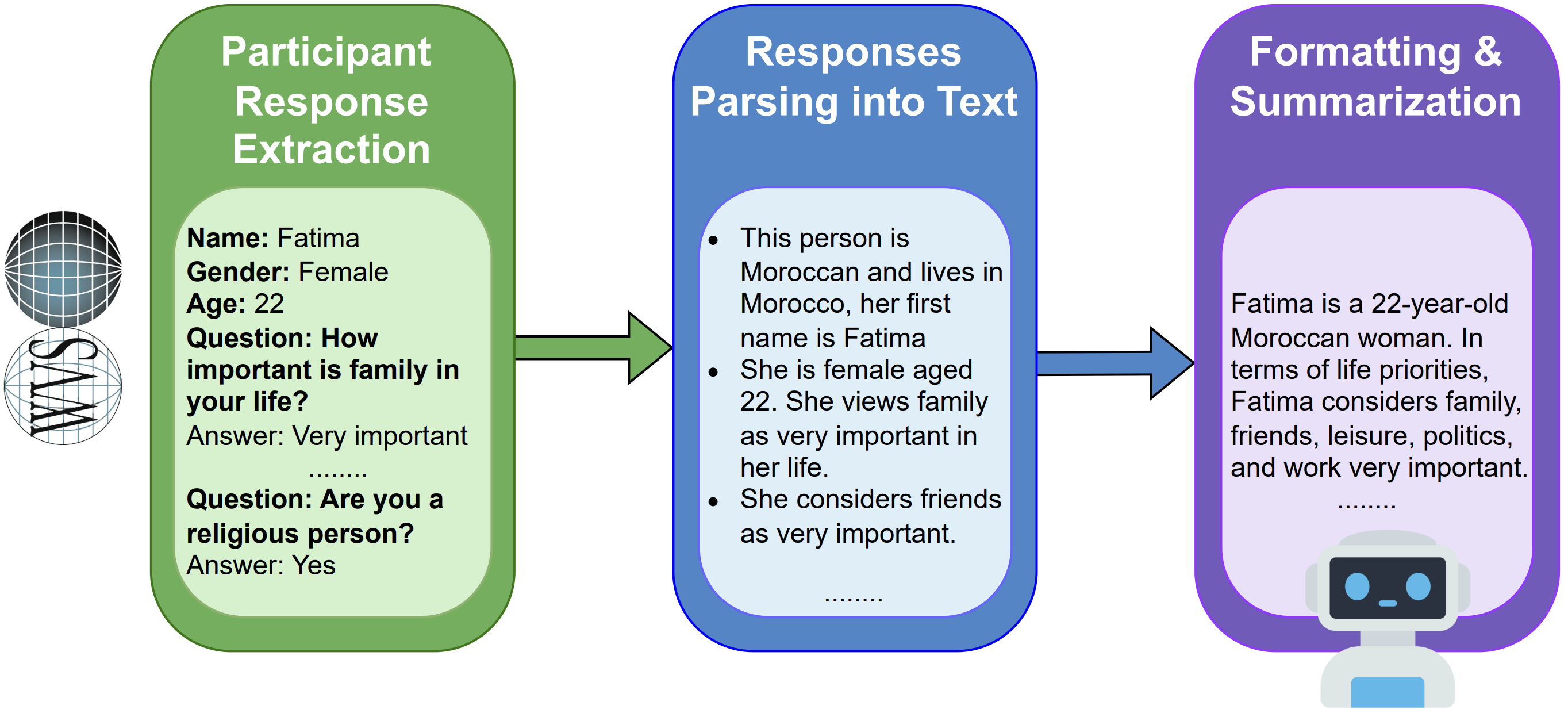
This step gives the model structured exposure to differences in priorities, beliefs, and social conditions inside the same country-level population. In the paper, the goal is not a generic “local speaker” persona, but a set of promptable profiles grounded in observed survey responses.
Pipeline summary
In summary, NileChat combines three ingredients at scale:
- a machine-translated educational layer built from 5.5 million Fineweb-edu texts for each dialect,
- a controlled synthetic layer built from personas, local news context, cultural heritage concepts, and dialectal expressions across stories, personal essays, blog posts, reviews, and conversations,
- and a retrieval layer built by querying cultural concepts on the web, keeping the top 20 non-social-media results, and parsing the returned pages.
The paper continues pretraining Qwen-2.5-3B on that mixture, then performs supervised fine-tuning for Egyptian and Moroccan variants. The main evaluations focus on understanding, translation, cultural knowledge, and value alignment.
Results
Compared with Qwen2.5-3B-Instruct, NileChat substantially improved understanding benchmarks, roughly doubled cultural knowledge scores on Palm for both dialects, and moved value alignment closer to World Values Survey response distributions across most measured dimensions. The paper presents these results as evidence that the combined MT, controlled generation, and retrieval pipeline improved local alignment beyond translation alone.
Evaluation of cultural value alignment in LLMs
One of the paper’s more useful contributions is its evaluation of cultural value alignment in LLM systems. Rather than treating generic reasoning benchmarks as a proxy for alignment, it evaluates cultural knowledge and compares model responses with World Values Survey response distributions.
This evaluation of cultural value alignment in LLMs matters because a model can be fluent in a target variety while still reflecting cultural bias in LLM behavior inherited from translated or globally dominant source data. In NileChat, the reported gains come not only from language adaptation, but also from explicit testing of whether the model’s answers move closer to community-level value patterns.
How the recipe could transfer to another community
The same structure could be adapted to another setting with a similar sequence:
- Define the target population in terms of language, cultural heritage, and values.
- Translate structured educational content for fluency and topical breadth.
- Build controlled prompts from local context, cultural concepts, linguistic expressions, and representative personas.
- Add search-based retrieval of culturally specific web pages and parse them into text.
- Evaluate understanding, translation, cultural knowledge, and value alignment explicitly.
That last step is easy to skip, but the paper shows why it matters: cultural alignment claims are stronger when they are tested against cultural knowledge and WVS-based value alignment, not inferred from generic benchmarks alone.
Limitations
The paper also notes several limitations:
- The method depends on a strong teacher model that can already generate the target low-resource variety.
- The supervised fine-tuning stage still relied heavily on translated data because native instruction data was scarce.
- A 3B model is still more susceptible to hallucination and incomplete information than larger architectures.
- Synthetic data generation is computationally expensive.
Summary
A central conclusion is that community alignment does not come from one prompt or one translated dataset. In NileChat, it comes from giving MT, controlled generation, and retrieval distinct roles across language, cultural heritage, and values.
This structure can transfer beyond Arabic. The exact dialects, cultural concepts, and evaluation sets will change, but the underlying principle stays the same: a model reflects a community more effectively when that community is encoded into the data pipeline on purpose.
For more in-depth detail about the data collection approach, see the paper.
Links
- Project resources (models and collected datasets): UBC-NLP NileChat collection
- Paper: NileChat: Towards Linguistically Diverse and Culturally Aware LLMs for Local Communities
Disclaimer (March 21, 2026): The latest version of this blog post was post-edited and formatted using an LLM.