Unsupervised Machine Translation in the Age of LLMs
Published:
Behind the Paper
For years, machine translation improved by scaling data. But scaling parallel data is not an option for most languages. In the LLM era, that bottleneck did not disappear. Few-shot prompting works best when good translation examples already exist, and for many language pairs they do not. In our recent paper, we asked a harder question: can we mine those examples automatically and still translate well?[4]
Paper summary: this post explains why unsupervised machine translation still matters, how in-context learning changes the problem, and how self-mined examples can improve multilingual LLM translation for low-resource languages without large parallel corpora.
This article is especially relevant to unsupervised machine translation, low-resource translation, in-context learning for machine translation, and multilingual LLM adaptation.
What is unsupervised MT?
Translation without human-aligned sentence pairs, bootstrapped from monolingual text and weak cross-lingual signals.[2][4]
What changed with LLMs?
LLMs made few-shot translation practical, but example quality and example selection still matter a lot.[1][3]
What our paper adds
We self-mine word pairs, turn them into weak sentence examples, and rank the best demonstrations with similarity filtering plus BM25.[4]
What is unsupervised machine translation?
Direct answer: Unsupervised machine translation (UMT) is translation between languages without human-labeled parallel sentences. Classical UMT starts from monolingual corpora, a weak cross-lingual initialization, and iterative back-translation that gradually improves translation quality.[2]
This line of work matters because conventional machine translation depends heavily on large parallel corpora, while many language pairs have little or no such data. One of the key insights in early UMT was that monolingual text is much easier to obtain than aligned bitext, so the right question is not only “How do we get more labels?” but also “How far can we go without them?”[2]
A useful mental model comes from the 2018 UMT literature: first align the problem just enough to get off the ground, then rely on language modeling, denoising, and back-translation to iteratively refine the system. That recipe turned an ill-posed task into something trainable even before LLM prompting entered the picture.[2]
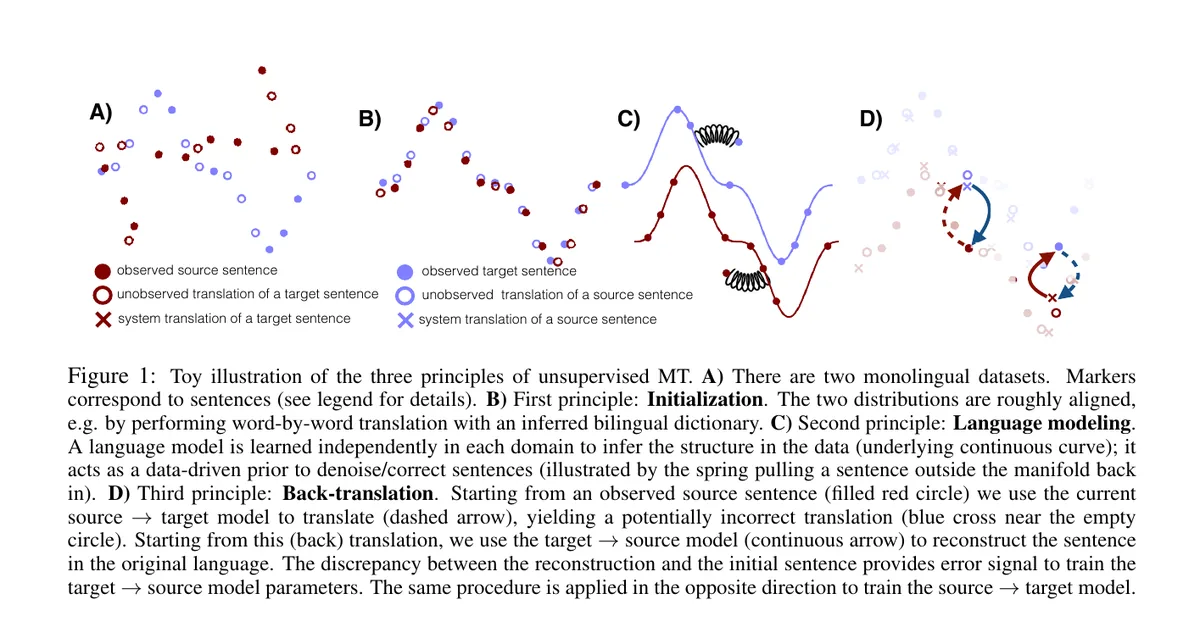
UMT in the era of LLMs and in-context learning
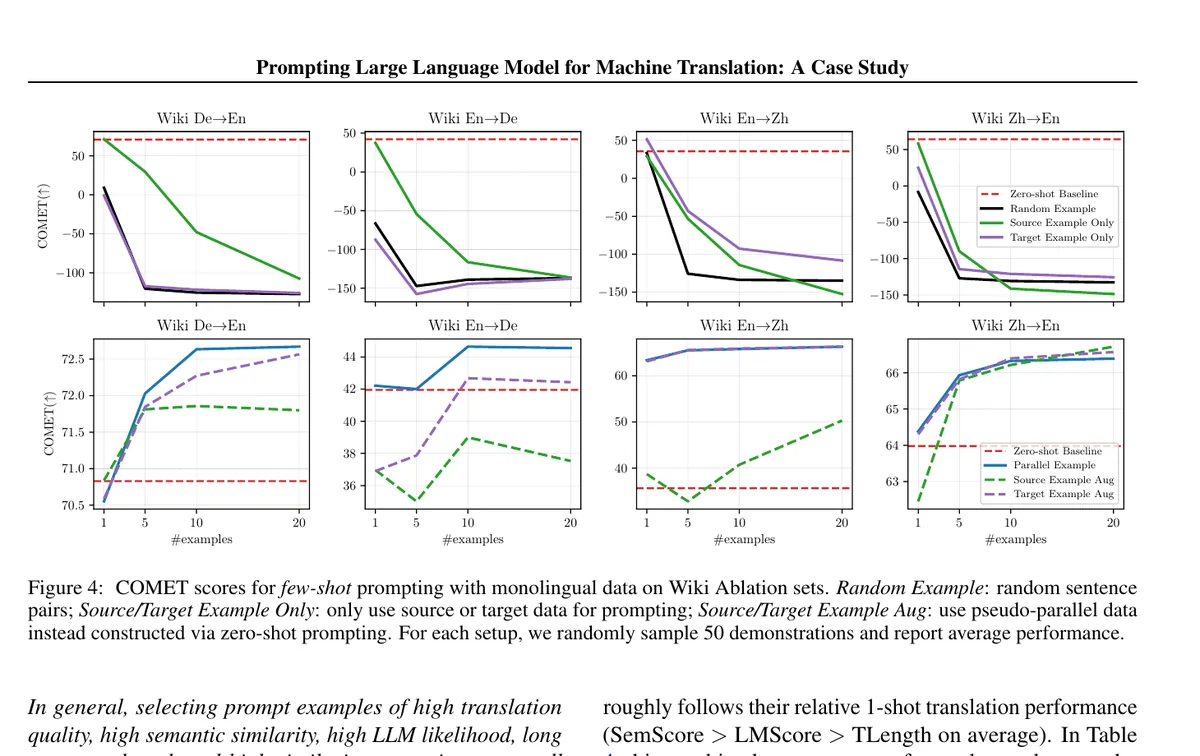
Large language models changed the interface of translation. Brown et al. framed few-shot learning as giving the model a small number of task demonstrations directly in the prompt, with no gradient updates at inference time. In that setup, a few-shot translation prompt can be as simple as repeated source sentence and target translation pairs followed by the new source sentence to translate.[1]
That is powerful, but it does not solve the hardest part for low-resource translation: where do those demonstrations come from? Brown et al. explicitly note that few-shot learning still requires a small amount of task-specific data. For machine translation, later work showed that the number and quality of prompt examples matter, that performance varies with prompt design, and that directly using monolingual examples can hurt translation while pseudo-parallel examples help.[1][3]
The bottleneck moved, but it did not disappear: LLMs can translate with prompts, yet low-resource settings still suffer from a missing-example problem. The challenge is not only prompting the model, but also constructing the prompt when no parallel data exist.[3][4]
Our paper: self-mining in-context examples for unsupervised MT
One-sentence summary: we treat the missing-demonstration problem as an unsupervised mining problem: first mine reliable word translations, then use them to create and filter sentence-level examples that an LLM can use for translation in context.[4]
In our Findings of NAACL 2025 paper, we assume access to a multilingual LLM, vocabularies in the source and target languages, and a small amount of unlabeled text in each language. Importantly, the learning phase uses no human-labeled parallel data, and the paper emphasizes a data-scarce regime with fewer than 1,000 unlabeled sentences per language in the studied setup.[4]
1. Mine word pairs
Use zero-shot prompting to translate frequent source words, reverse the direction, keep consistent back-translations, and rank the remaining pairs by cross-lingual similarity to retain high-quality lexical anchors.[4]
2. Bootstrap with word-level prompts
Feed the best mined word pairs back into the model as in-context examples, refining the word inventory before moving to sentence-level translation.[4]
3. Create weak sentence translations
Translate sentences word by word to obtain rough but semantically useful sentence pairs. They are noisy, but they preserve enough meaning to seed the next stage.[4]
4. Select the right demonstrations
Back-translate to obtain more natural pairs, then choose input-specific examples with a two-step filter: similarity threshold first, BM25 ranking second. The final method is TopK+BM25.[4]
Key idea: instead of assuming demonstrations already exist, the system manufactures them from unlabeled text and then ranks them for each test input. Example selection becomes part of the learning pipeline, not an afterthought.[4]
Results
We evaluated the approach with Llama-3 8B and Bloom 7B on 288 translation directions from FLORES-200. The headline result is that the unsupervised method can be comparable to, and sometimes better than, translation with regular in-context examples drawn from human-annotated data, while also outperforming prior UMT systems by an average of 7 BLEU points in the paper’s summary results.[4]
288 directions
Evaluation scale across FLORES-200 translation directions with two multilingual LLMs.[4]
+7 BLEU
Average improvement over prior state-of-the-art unsupervised MT methods reported in the paper's abstract.[4]
55.76 spBLEU
Average score for TopK+BM25 on the English-involving subset, competitive with regular human-annotated in-context learning.[4]
40.13 BLEU
WMT benchmark average in the paper's Table 2, ahead of the best listed baseline at 33.68.[4]
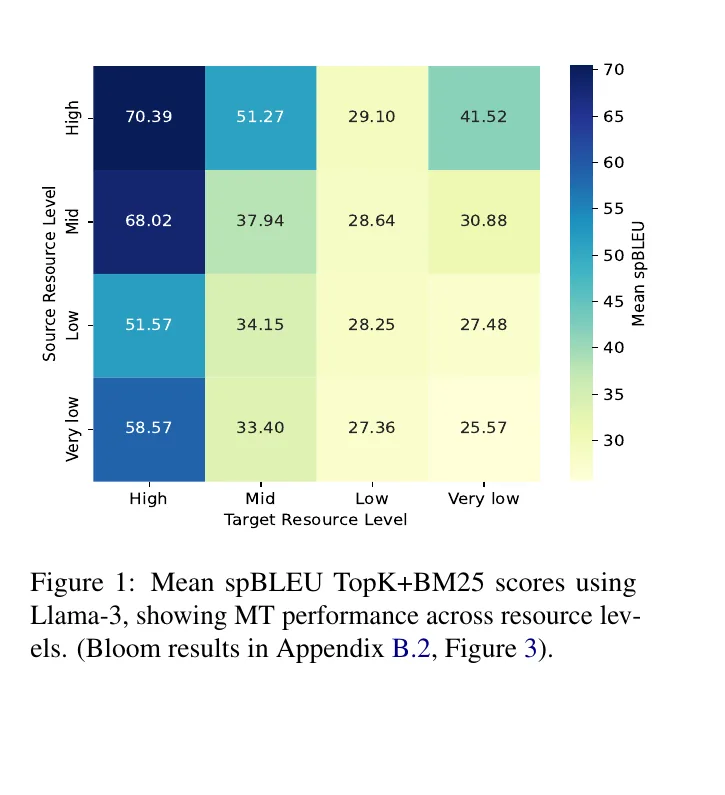
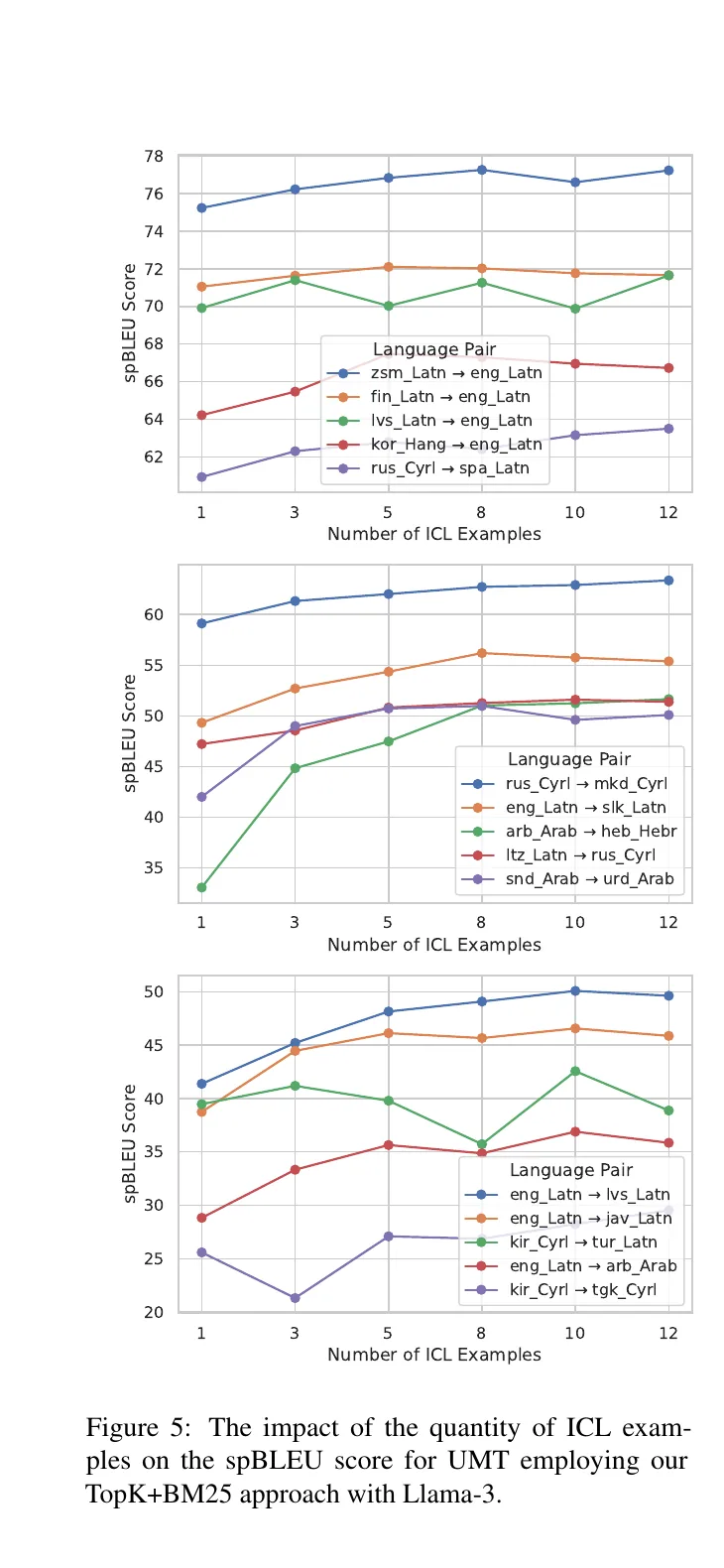
Two findings stood out to me. First, resource level still matters: even with strong multilingual LLMs, translation is easier when the target side is better represented. Second, better prompting is not just about the model. It is also about retrieval and filtering. In our experiments, a carefully selected unsupervised demonstration set was the difference between a rough translation and a competitive one.[4]
Why this matters for low-resource translation
The broader significance is straightforward. If translation quality depends on large curated bitexts, then many languages remain blocked by a data collection problem before they can benefit from new models. But if an LLM can bootstrap usable demonstrations from a small amount of unlabeled text, the entry cost drops dramatically.[2][4]
That does not mean the problem is solved. Low-resource translation remains harder, and our heatmap makes that visible. But it does mean the path forward looks different. Instead of waiting for perfect parallel corpora, we can start from weak lexical evidence, noisy sentence pairs, and strong multilingual priors, then iteratively mine something useful.[4]
My own takeaway is that unsupervised MT is newly relevant in the LLM era. Not because LLMs made supervision obsolete, but because they made bootstrapping supervision more plausible. For underrepresented languages, that distinction matters. It is the difference between “we cannot build this yet” and “we can begin with what we have.”[2][4]
Bottom line: if we can mine trustworthy in-context examples from unlabeled data, translation systems no longer have to wait for abundant parallel corpora before they become useful. That is a practical route toward broader language coverage in search, assistants, education, and public-facing digital tools.
FAQ
What is unsupervised machine translation?
It is translation without human-aligned sentence pairs. Instead of supervised bitext, the system has to bootstrap from monolingual data, weak lexical alignments, denoising, and back-translation.[2][4]
Is unsupervised MT the same as zero-shot translation?
No. Zero-shot translation is an inference setting where the model receives an instruction but no examples. In our work, the main problem is how to create reusable in-context examples from unlabeled data so the model can translate more reliably than plain zero-shot prompting.[1][4]
Why not just use monolingual examples as demonstrations?
Prior work on prompting for machine translation found that monolingual-only demonstrations generally hurt translation, whereas pseudo-parallel examples created through zero-shot back-translation or forward translation are much more effective.[3]
How much unlabeled data does the approach assume?
The paper studies a setting with fewer than 1,000 unlabeled sentences in each language, together with source and target vocabularies, a multilingual LLM, and an unsupervised sentence similarity function.[4]
What is the main empirical takeaway?
The paper reports that self-mined in-context examples can match or beat regular human-annotated in-context learning in many settings, while improving on previous UMT systems by an average of 7 BLEU points in the paper’s summary results.[4]
References
- Brown, T. B., Mann, B., Ryder, N., et al. (2020). Language Models are Few-Shot Learners. NeurIPS. PDF
- Lample, G., Ott, M., Conneau, A., Denoyer, L., and Ranzato, M. A. (2018). Phrase-Based and Neural Unsupervised Machine Translation. EMNLP. PDF
- Zhang, B., Haddow, B., and Birch, A. (2023). Prompting Large Language Model for Machine Translation: A Case Study. ICML / PMLR. PDF
- El Mekki, A., and Abdul-Mageed, M. (2025). Effective Self-Mining of In-Context Examples for Unsupervised Machine Translation with LLMs. Findings of NAACL 2025. PDF
Links
- Project code: https://github.com/UBC-NLP/sm-umt
- Paper: https://aclanthology.org/2025.findings-naacl.238/
Disclaimer (April 04, 2026): The latest version of this blog post was post-edited and formatted using an LLM.