Alexandria: A Dialectal Arabic Machine Translation Dataset for Real-World Arabic MT
Published:
Dataset Release
Arabic machine translation still has a large gap between formal written Arabic and the Arabic people use every day. Most Arabic MT systems are strongest on Modern Standard Arabic (MSA), but real conversations across the Arab world happen in local dialects, with city-level variation, code-switching, gendered forms, and domain-specific vocabulary. Alexandria was built to make that gap measurable, trainable, and harder to ignore.[1]
TL;DR: Alexandria is a large, community-driven, human-translated Dialectal Arabic machine translation dataset with 107K turns and 34,488 conversations across 13 Arab countries and 11 domains with high social impact. It is designed for English-Dialectal Arabic MT, Arabic dialect benchmarking, low-resource machine translation research, context-aware translation, and evaluation of Arabic-aware LLMs.[1][2]
This post is written for researchers, engineers, and dataset builders searching for an Arabic machine translation dataset, a Dialectal Arabic MT benchmark, an English Arabic translation dataset, or a low-resource machine translation resource for Arabic dialects.
107K turns
Parallel English and Dialectal Arabic turns grouped into multi-turn conversations.[1]
13 countries
Coverage across Egyptian, Levantine, Gulf, Nile, and Maghrebi dialect groups.[1]
11 domains
Healthcare, education, agriculture, legal and financial services, logistics, workplace communication, tourism, and more.[2]
City-level signal
Metadata goes beyond broad labels such as "Levantine" or "Maghrebi" and supports finer dialect analysis.[1]
What is Alexandria?
Direct answer: Alexandria is a multi-domain, human-translated English-to-Dialectal Arabic and Dialectal Arabic-to-English machine translation dataset. It contains parallel, turn-aligned multi-turn conversations from 13 Arab countries, with metadata for country, city or sub-dialect, domain, persona role, speaker-addressee gender configuration, and split.[1][2]
The dataset was created because Arabic MT has a structural evaluation problem. A system can look strong on formal MSA and still fail when users write or speak Egyptian Arabic, Moroccan Darija, Palestinian Arabic, Sudanese Arabic, Mauritanian Hassaniya, Omani Arabic, or Yemeni Arabic. This is not only a vocabulary issue. Dialects differ in morphology, syntax, politeness, register, borrowed words, and gender marking.
Earlier dialectal Arabic MT resources helped the field, but many were limited by sentence-level structure, narrow domains, coarse dialect labels, or short utterances. Alexandria expands the design in four directions at once: conversation-level context, broader domain coverage, community translation and revision, and richer metadata for dialect and gender-sensitive analysis.[1]
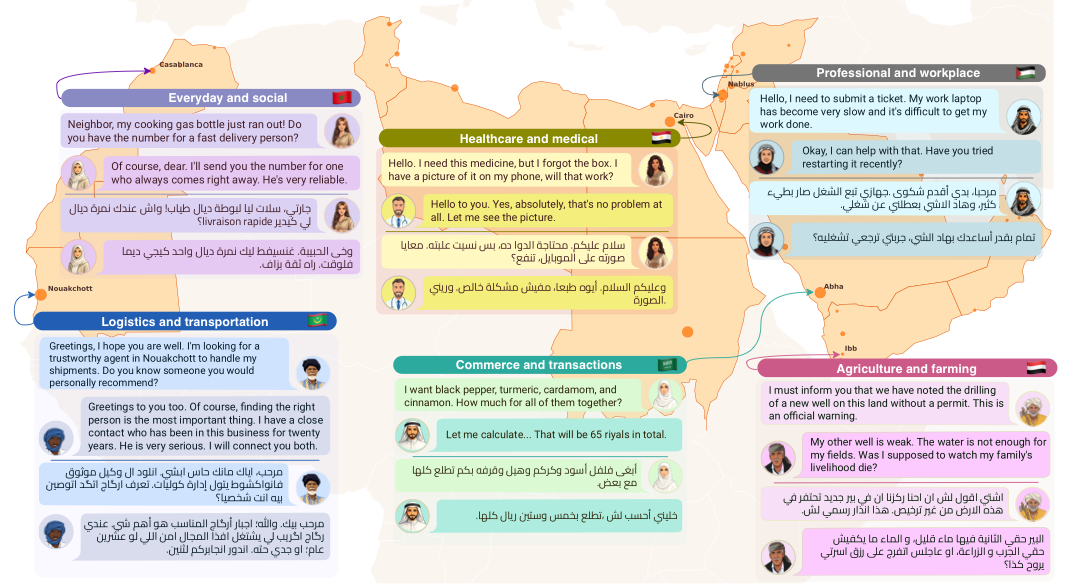
What is inside the dataset?
Alexandria contains 34,488 multi-turn conversations and approximately 107K total turns. Each example belongs to a conversation rather than an isolated sentence, which makes it useful for context-aware machine translation and dialogue-oriented LLM evaluation.[1]
The 13 country-level dialect groups are:
- Egypt
- Jordan
- Lebanon
- Libya
- Mauritania
- Morocco
- Oman
- Palestine
- Saudi Arabia
- Sudan
- Syria
- Tunisia
- Yemen
The 11 domains are:
- Agriculture and farming
- Commerce and transactions
- Construction and real estate
- Education and academia
- Energy and resources
- Everyday and social communication
- Healthcare and medical communication
- Legal and financial communication
- Logistics and transportation
- Professional and workplace communication
- Tourism and hospitality
That domain mix matters. Many dialectal Arabic datasets focus on travel phrases, web text, or general-purpose short sentences. Alexandria targets situations where translation quality has real consequences: medical instructions, financial services, academic communication, logistics, workplace coordination, agriculture, and public-facing services.
Key point: Alexandria is not just an Arabic dialect list. It is a metadata-rich benchmark for testing whether a model can preserve meaning, produce authentic local dialect, respect gendered forms, and remain robust across domains and cities.
Practical use cases
1. English-to-Dialectal Arabic machine translation
The most direct use case is training or evaluating systems that translate English into regional Arabic dialects. This is the harder direction in the experiments because the model must generate dialect-authentic Arabic, not merely understand it.[1]
This is useful for MT systems, multilingual assistants, customer support, healthcare communication, education platforms, localization workflows, and public-service chatbots that need to speak to users in familiar local Arabic.
2. Dialectal Arabic-to-English translation
Alexandria also supports dialect-to-English translation. In the experiments, models generally perform better in this direction than in English-to-dialect translation, which suggests that current systems are often better at understanding dialectal input than producing authentic dialectal output.[1]
This direction is valuable for search, moderation, multilingual analytics, public-interest monitoring, and accessibility tools that need to interpret dialectal Arabic content.
3. Arabic LLM evaluation
Alexandria is a benchmark for Arabic-aware LLMs. We evaluated 24 Arabic-capable models under turn-level, context-level, and conversation-level translation settings. This makes the dataset useful for comparing closed and open models, measuring translation robustness, and checking whether improvements hold across dialects rather than only on high-resource varieties.[1]
4. Context-aware and conversation-level MT
Many translation benchmarks are sentence-level. Alexandria is organized as multi-turn conversations, so it can test whether a system uses previous turns to translate the current turn more accurately. This matters for pronouns, speaker roles, tone, deixis, and other conversational dependencies.
5. City-level and sub-dialect robustness
Arabic dialects are not clean country-level blocks. A Palestinian rural variety can differ from an urban one. Omani sub-dialects differ across cities and regions. Moroccan, Tunisian, Mauritanian, Egyptian, Saudi, and Yemeni varieties all carry internal diversity. Alexandria’s city-anchored metadata allows researchers to ask whether a model is robust within a country, not only across countries.[1]
6. Gender-aware machine translation
Arabic has many gender-marked forms. Alexandria includes speaker-addressee gender configurations, which makes it useful for evaluating whether translations preserve gender agreement and address forms. This is especially relevant for dialogue systems, because the gender of the speaker and the addressee can affect pronouns, verbs, adjectives, and social register.[1]
7. Code-switching and register research
Many Arabic-speaking communities naturally mix Arabic with English, French, or other locally common languages, especially in technical, workplace, healthcare, and education settings. Alexandria explicitly allows conventional borrowed terms when they are natural in the target community. That makes it useful for studying code-switching, register control, and the boundary between dialect, MSA, and borrowed terminology.[1]
How Alexandria was built
Alexandria was built through a six-month community-driven process involving 55 contributors from 13 Arab countries. This matters because the dataset is not just translated “into Arabic.” It is translated into local varieties by people tied to the target communities, with country leads coordinating local examples, onboarding, guideline interpretation, and quality control.[1]
The community design was central to the dataset. Contributors represented city-anchored dialectal varieties, and the project used country teams rather than a single centralized annotation pool. That structure allowed the dataset to capture choices a generic Arabic translation process would often flatten: whether a phrase sounds Egyptian or Sudanese, whether a Moroccan speaker would naturally code-switch into French, whether an Omani term fits one locality but not another, and whether the gendered form matches the speaker and addressee.
Project coordination was also part of the data quality process. The team used weekly project checks, a shared Slack workspace, bi-weekly reminders, and country-lead meetings every few weeks to surface recurring issues and refine the workflow.[1]
The pipeline had three main phases.
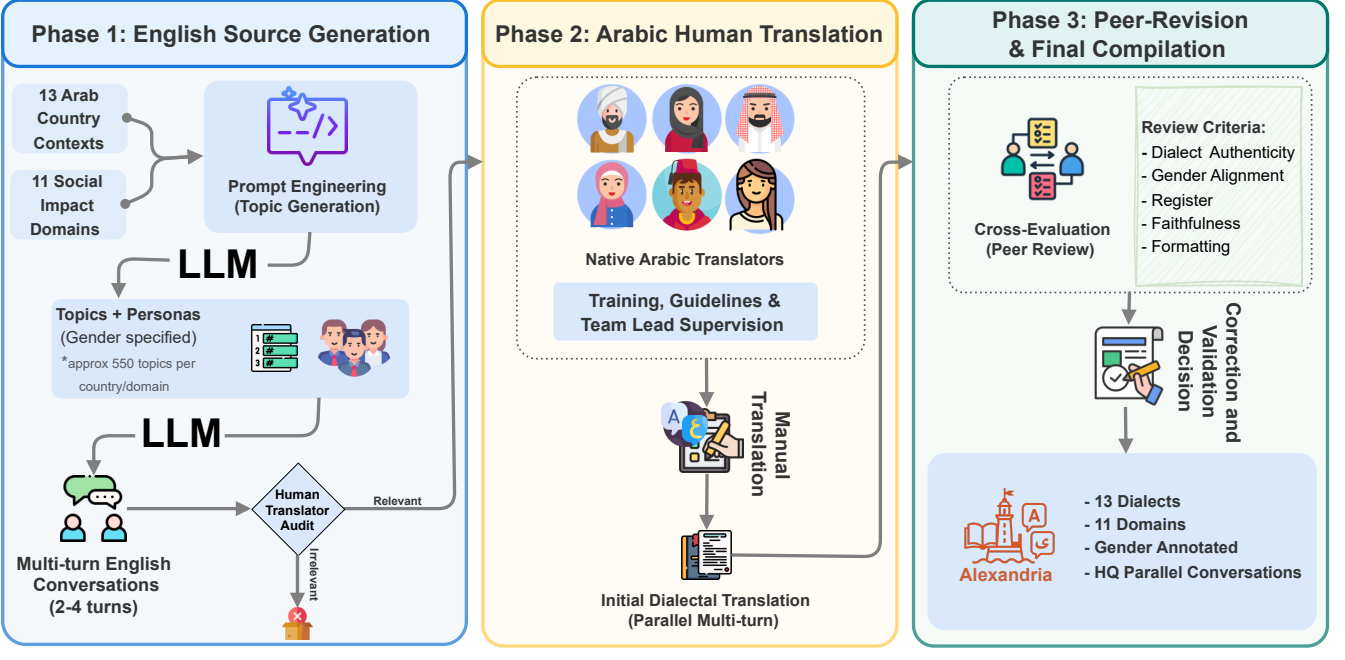
1. Source creation
Gemini-2.5 Pro generated English multi-turn conversations conditioned on country, domain, topic, persona, and gender configuration.[1]
2. Human translation
Native speakers translated the English conversations into their local Arabic dialects while preserving meaning, tone, persona, register, and gender direction.[1]
3. Peer revision
A second contributor from the same country reviewed translations for dialect authenticity, gender alignment, register, faithfulness, punctuation, and code-switching consistency.[1]
Source generation and screening
The English source conversations were generated in a controlled way before translation. For each country-domain pair, the pipeline generated 55 subdomains and 10 topics per subdomain, giving 550 topic specifications per country-domain. These topics were then used to create 2-4 turn English conversations conditioned on the target country, domain, persona, and gender configuration.[1]
This source step was not treated as automatically correct. Contributors audited source conversations before translating them and skipped examples that did not fit local context, contained problematic cultural assumptions, or introduced factual issues. On average, 2.94% of source sentences were skipped as irrelevant. This is a useful reminder for multilingual dataset construction: LLM-generated source text can help scale coverage, but community review is what prevents source artifacts from becoming target-side noise.[1]
Human translation and local dialect decisions
The translation guidelines asked contributors to preserve semantic faithfulness while using natural local dialect rather than forcing the output into MSA. Translators were allowed to use Arabic script without enforcing a single standardized spelling system, which is important for dialectal Arabic because many varieties do not have one universally accepted orthography.
The guidelines also allowed code-switching when it was conventional in the target community. That detail matters for domains such as healthcare, education, commerce, logistics, and workplace communication, where English, French, or other borrowed terms may be the most natural local choice.
Peer revision and final compilation
The revision phase was human-only. Each translated conversation was reviewed by another participant from the same country, who checked dialect authenticity, gender alignment, register, faithfulness, punctuation, and code-switching consistency. Reviewers marked each item as accepted, minor edit, or major issue. If a reviewer came from a different regional variety inside the same country, the guidelines restricted them to mechanical edits rather than rewriting another local variety into their own.[1]
The revision results are important. In the human-only revision phase, 68.4% of turns remained unchanged, 30.6% received minor edits, and 1% were flagged for major issues. The final revised data received high average quality scores for dialectal authenticity, register appropriateness, and semantic faithfulness.[1]
Splits built for evaluation
Alexandria is released with training, public development, public test, and private test splits. The public development and test sets were stratified across dialect groups, gender configurations, and translators. This design makes the dataset useful not only for training, but also for fairer evaluation and future shared tasks or leaderboards.[1]
Data creation takeaway: for Dialectal Arabic machine translation, quality does not come from translation volume alone. It comes from community anchoring, local review, gender-aware metadata, and a revision process that respects within-country dialect diversity.
What the experiments show
Result summary: current Arabic-aware LLMs are much better at preserving meaning than producing dialect-authentic Arabic. Dialect-to-English translation is consistently easier than English-to-dialect translation. Maghrebi varieties, especially Mauritanian Arabic, remain among the hardest settings. Code-switching often lowers automatic translation scores. Metadata helps some models, but not all models consistently use it well.[1]
The evaluation is useful because it avoids treating “Arabic translation” as one flat task. We evaluated 24 Arabic-capable LLMs across turn-level, context-level, and conversation-level settings. The main discussion focuses on the context-level setting because it best matches realistic dialogue MT: the model translates the current turn while seeing previous turns, but not future turns. Conversation-level translation gives higher raw scores, but it is a more permissive offline setup.[1]
We chose the automatic metrics carefully. We reported spBLEU and chrF++, and avoided COMET because model-based MT metrics are less reliable for dialectal Arabic. Since spBLEU and chrF++ are highly correlated in our experiments, we used spBLEU for the main automatic analysis and reserved chrF++ for the appendix.[1]
Dialect-to-English is easier than English-to-dialect
Across the evaluated models, Alexandria shows a strong directional asymmetry. Models perform better when translating dialectal Arabic into English than when translating English into dialectal Arabic. This is a central finding for Arabic MT and LLM evaluation: understanding a dialect is not the same as generating it naturally.[1]
For product builders, this means a model that can answer questions about dialectal Arabic input may still sound unnatural when asked to generate local Arabic. For researchers, it means evaluation should separate comprehension from dialect-authentic generation.
This directional asymmetry is one of the most actionable findings. If a system is meant to serve Arabic-speaking users, it is not enough to report dialect-to-English scores. English-to-dialect generation should be tested separately because that is where models are more likely to drift into MSA, generic Arabic, or the wrong regional form.
Maghrebi dialects remain especially difficult
Performance varies heavily by dialect group. The models tend to do better on Egyptian and Levantine varieties, likely because these varieties are better represented in training data. Maghrebi dialects are harder, and Mauritanian Arabic is consistently among the most challenging in the benchmark.[1]
This finding matters for low-resource machine translation because the hardest dialects are often the ones most in need of better resources. A benchmark that only averages across all Arabic varieties can hide these gaps.
We also analyze lexical overlap with MSA and find that translation quality tends to be higher when dialectal references are lexically closer to MSA. This helps explain why varieties with stronger distance from MSA, including Maghrebi varieties, are more difficult for current models. The important evaluation lesson is that “Arabic” performance can be inflated by dialects that are closer to MSA while masking failure on more distant varieties.[1]
City-level evaluation reveals stable sub-dialect difficulty
Alexandria also evaluates selected sub-dialects within countries. We find that relative sub-dialect rankings are broadly consistent across model families. In other words, some sub-dialects are systematically harder across models, not just unlucky for one model.[1]
That is exactly why city-level metadata matters. Without it, a benchmark may say “Palestinian Arabic” or “Omani Arabic” while missing important variation inside the label.
Domain rankings are stable across models
Alexandria covers 11 domains, and our experiments show that model ranking is fairly stable across those domains. The strongest models remain strong across topics, and smaller open-weight models remain lower-tier in this setup. We find limited evidence that one model is uniquely specialized for a particular domain under the tested prompting conditions.[1]
This is useful for benchmarking because it suggests Alexandria can expose general Arabic dialect MT strength, not only topic-specific tricks.
At the same time, domain coverage remains important. Stable model rankings do not mean domains are interchangeable. Technical domains still expose lexical gaps, MSA leakage, and code-switching pressure that would be invisible in a benchmark made only of everyday or tourism phrases.
LLMs beat NLLB in the tested dialects, but metadata is mixed
We compare a subset of LLMs against NLLB-200-3.3B on the nine Alexandria dialects supported by NLLB. The evaluated LLMs outperform NLLB across those supported dialects, even without metadata in the prompt.[1]
The metadata ablation is more nuanced. Full metadata helps Command-A in some cases, but the gains are not universal. For some models and dialects, adding all metadata has little effect or even hurts. This suggests that models differ in how well they use structured context such as participant gender, country, domain, and role information.
Code-switching hurts many models
Alexandria makes code-switching measurable. We compare translation quality for sentences with and without Latin-script tokens and find that code-mixing generally degrades performance for many dialects, including Egyptian, Jordanian, Lebanese, Moroccan, Palestinian, and Tunisian Arabic.[1]
This is a practical result. Real Arabic users often code-switch, especially in technical, business, medical, and educational settings. A model that only handles clean Arabic script is not enough for production-grade dialectal Arabic MT.
This is also where Alexandria becomes useful beyond translation scores. Because code-switching is measurable by dialect and domain, the dataset can support targeted evaluation of whether a system handles French-influenced Moroccan or Tunisian professional language, English-heavy workplace vocabulary, or technical terms that speakers would not naturally force into colloquial Arabic.
Reasoning does not automatically improve translation
The experiments also compare reasoning and non-reasoning configurations for selected models. Reasoning generally does not help and often hurts translation performance, with the main exception being Gemini-3-Flash, where reasoning improved average spBLEU by about 2.0 points for English-to-dialect and about 0.4 points for dialect-to-English.[1]
The broader lesson is that “more thinking” is not automatically better for translation. Translation needs faithful, fluent, locally appropriate output, and reasoning traces may not target that objective.
Evaluation insights for Arabic MT builders
The practical evaluation lessons from Alexandria are:
- Evaluate both directions: dialect-to-English and English-to-dialect answer different questions.
- Report dialect-level results, not only macro averages over Arabic.
- Separate semantic adequacy from dialect authenticity because a translation can be meaningful but still sound non-native.
- Include code-switching and technical domains because they are part of real Arabic use.
- Test whether metadata helps your specific model instead of assuming that more metadata always improves translation.
- Use human evaluation when dialectness matters, since automatic metrics do not fully capture register, locality, or naturalness.
What the human evaluation adds
Automatic metrics are useful, but dialectal Arabic translation needs human judgment. Alexandria’s human evaluation separates three dimensions: semantic adequacy, gender accuracy, and dialectness or fluency.[1]
The results show a clear pattern:
- Gender accuracy is usually high, often above 90%, when gender constraints are explicit.
- Semantic adequacy is generally above 3 out of 5 across dialects.
- Dialectness and fluency are lower, sometimes close to 2 out of 5 for difficult model-country pairs.
This is one of the most important conclusions from Alexandria. Current models often know what the sentence means, but they do not always know how a native speaker in the target dialect would say it. They preserve semantics better than dialect authenticity.
Among the human-evaluated systems, Gemini-3-Flash and Command-A define the strongest adequacy-dialectness trade-off, while some large models still produce weaker dialectness despite preserving meaning.[1]
How to load Alexandria
The dataset is available on Hugging Face at UBC-NLP/alexandria. You need to review and accept the dataset access conditions on Hugging Face before loading the files.[2]
from datasets import load_dataset
repo_id = "UBC-NLP/alexandria"
# Example: Morocco subset
train_data = load_dataset(repo_id, name="MA", split="train")
test_data = load_dataset(repo_id, name="MA", split="test")
first_conv = train_data[0]
eng_turn = first_conv["english_conversation"][0]
dialect_turn = first_conv["dialectal_conversation"][0]
print(f"English: {eng_turn['text']}")
print(f"Dialect: {dialect_turn['text']}")
Responsible use and limitations
Alexandria is intended for research, evaluation, and model development around Dialectal Arabic MT and Arabic-aware LLMs. Before training or redistributing outputs, users should check the Hugging Face access conditions and the CC BY-NC-ND 4.0 license.[2]
FAQ
What is Alexandria?
Alexandria is a multi-domain Dialectal Arabic machine translation dataset and benchmark. It contains English and Dialectal Arabic multi-turn conversations translated and revised by native speakers from 13 Arab countries.[1]
Is Alexandria an Arabic machine translation dataset or an LLM benchmark?
It is both. Alexandria can be used as a training resource for English-Dialectal Arabic MT and as a benchmark for Arabic-capable LLMs under dialect, domain, context, and gender variation.[1][2]
Why is Dialectal Arabic machine translation hard?
Dialectal Arabic is highly variable across countries, cities, social contexts, and domains. It also mixes with MSA and other languages. A model must preserve meaning while producing locally natural vocabulary, morphology, gender marking, and register.
Which dialects are included?
Alexandria covers Egypt, Jordan, Lebanon, Libya, Mauritania, Morocco, Oman, Palestine, Saudi Arabia, Sudan, Syria, Tunisia, and Yemen, with finer sub-dialect or city-level metadata where available.[1]
What makes Alexandria useful for low-resource machine translation?
Many Arabic dialects have limited high-quality parallel data. Alexandria provides human-translated, peer-revised, multi-domain parallel conversations for dialects that are often underrepresented in MT benchmarks and training data.
What did the experiments conclude?
The main conclusion is that current Arabic-aware LLMs are better at meaning preservation than dialect-authentic generation. Dialect-to-English is easier than English-to-dialect, Maghrebi varieties are among the hardest, code-switching often lowers quality, and metadata helps only when the model can use it effectively.[1]
Can Alexandria be used for gender-aware MT?
Yes. Alexandria includes speaker-addressee gender configurations, making it useful for studying whether translation systems preserve gendered Arabic forms in dialogue.[1]
Summary
Alexandria shows that the next step for Arabic machine translation is not simply more MSA data or broader language labels. The field needs benchmarks that reflect how Arabic is actually used: local dialects, city-level variation, multi-turn context, gendered speech, code-switching, and high-impact domains.
The strongest result is also the simplest: models often understand dialectal Arabic better than they can generate it. Alexandria gives researchers and builders a way to measure that gap directly, improve Arabic MT systems, and build more culturally and linguistically inclusive language technology.
References
- El Mekki, A., Magdy, S. M., Atou, H., AbuHweidi, R., Qawasmeh, B., Nacar, O., and others. (2026). Alexandria: A Multi-Domain Dialectal Arabic Machine Translation Dataset for Culturally Inclusive and Linguistically Diverse LLMs. ACL 2026 Main. arXiv
- UBC-NLP. (2026). Alexandria Dataset Card. Hugging Face Dataset. https://huggingface.co/datasets/UBC-NLP/alexandria
- UBC-NLP. Alexandria GitHub Repository. https://github.com/UBC-NLP/Alexandria
- Alexandria Project Website. https://alexandria.dlnlp.ai/
Links
- arXiv article: https://arxiv.org/abs/2601.13099
- Dataset: https://huggingface.co/datasets/UBC-NLP/alexandria
- GitHub repository: https://github.com/UBC-NLP/Alexandria
- Project website: https://alexandria.dlnlp.ai/
Disclaimer (May 03, 2026): The latest version of this blog post was post-edited and formatted using an LLM.