WVS2Persona: World Values Survey Wave 7 Personas for Culture-Aware AI
Published:
Dataset Release
In recent research, we built NileChat, a culturally aligned LLM for Egyptian and Moroccan Arabic communities. A key part of that work was feeding local personas to the LLM so controlled synthetic data generation could reflect community values, not only surface-level language patterns. For NileChat, those personas were parsed from World Values Survey records for Morocco and Egypt, because these were the two use cases in the paper. With WVS2Persona, I am releasing the same kind of persona resource for all countries covered in this dataset so other researchers and builders can reuse the idea beyond the original NileChat setting.[1][2]
TL;DR: WVS2Persona is Hugging Face dataset of 97,220 respondent-level persona descriptions derived from World Values Survey Wave 7 records, organized into 66 country subsets.[2]
This dataset is relevant to culture-aware AI, LLM cultural alignment, persona-based prompting, social values modeling, and evaluation of value-sensitive generation.
66 country subsets
Country-level configurations such as Morocco, Egypt, United_States, India, and Brazil.[2]
97,220 personas
One textual persona per WVS Wave 7 respondent record.[2]
NileChat method
The construction follows the WVS-to-persona direction used in NileChat for culturally grounded generation.[1]

From NileChat to WVS2Persona
The motivation comes directly from NileChat. In NileChat paper, we proposed a methodology for adapting LLMs to local communities by considering three axes together: language, cultural heritage, and cultural values. The values component is where WVS-derived personas matter. They make it possible to condition data generation on concrete social profiles instead of vague labels such as “local speaker” or “person from country X.”[1]
In NileChat, this idea was applied to Egyptian and Moroccan Arabic. WVS2Persona expands the persona resource itself across the countries available in the release, making it easier for other researchers and builders to reuse the same type of value-grounded conditioning outside the original NileChat experiments.
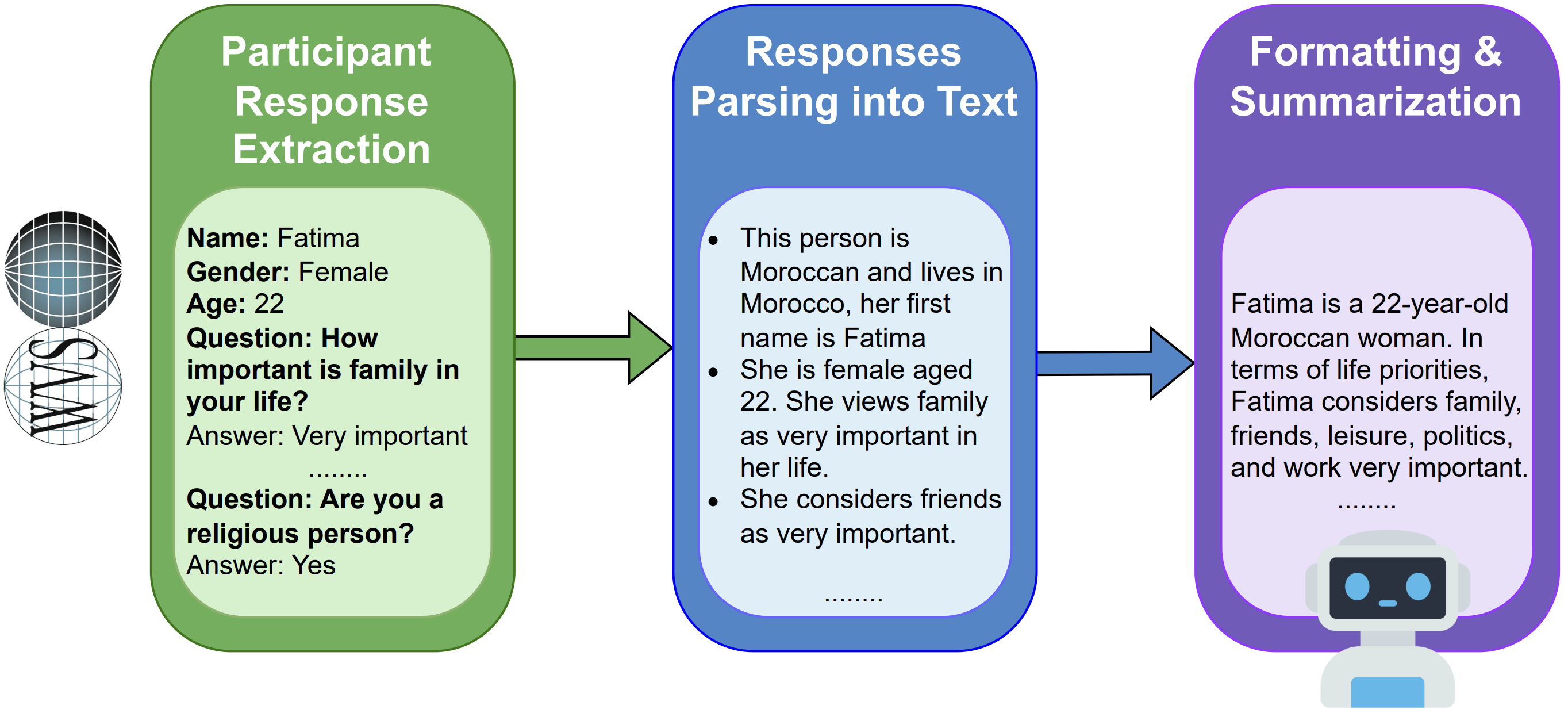
There is one important release detail. The current WVS2Persona dataset provides full deterministic persona descriptions generated from decoded core WVS questionnaire variables. The concise, summarized persona style used for compact prompting in NileChat is planned as a future extension.[2]
What is inside the dataset?
WVS2Persona is organized by country as Hugging Face subsets. Each subset has one train split and two columns:
persona_id: a stable identifier for the persona record.persona: a full English persona description grounded in the respondent’s decoded WVS Wave 7 core-questionnaire answers.
The personas are respondent-level renderings. They are not cluster centroids, not invented archetypes, and not synthetic summaries of a demographic group. That distinction matters because a country does not have one value profile. A useful culture-aware dataset should preserve within-country variation across age, gender, education, religion, political attitudes, trust, well-being, economic values, family norms, security concerns, and other survey dimensions.
The released personas use only the WVS Wave 7 core questionnaire sections, including social values, happiness and well-being, trust and organizational membership, economic values, corruption, migration, security, science and technology, religious values, ethical values, political participation, political culture, and demographics.[2][3]
Key point: WVS2Persona is a bridge between social survey data and LLM workflows. It turns structured survey responses into text that can be retrieved, prompted, summarized, filtered, and inspected by the same tools already used for language model experimentation.
Why this kind of dataset matters
Most language model datasets are good at representing what people write online. They are much weaker at representing how different communities answer questions about family, trust, religion, democracy, security, migration, gender norms, work, technology, and moral judgments. Those topics are central to cultural alignment, but they are not reliably captured by web text alone.
That gap matters for three reasons.
First, culture-aware AI needs internal variation. A single country label is too coarse. WVS2Persona keeps respondent-level diversity visible, which helps avoid collapsing a society into one stereotype.
Second, persona-grounded generation is easier to audit than free-form prompting. A model can be conditioned on a specific textual profile, and the researcher can inspect the profile that shaped the output.
Third, evaluation can move beyond generic benchmarks. If a model claims to represent a community, researchers can test whether its answers, explanations, or generated examples reflect the range of values observed in survey-grounded profiles rather than only dominant internet priors.
How to load WVS2Persona
The dataset is available on Hugging Face at 3ebdola/wvs2persona.[2] Each country is loaded as a subset/config.
from datasets import load_dataset
repo_id = "3ebdola/wvs2persona"
ds_morocco = load_dataset(repo_id, "Morocco", split="train")
print(ds_morocco)
print(ds_morocco.column_names)
print(ds_morocco[0]["persona_id"])
print(ds_morocco[0]["persona"][:500])
Country names with spaces use underscores in the subset name:
from datasets import load_dataset
repo_id = "3ebdola/wvs2persona"
ds_us = load_dataset(repo_id, "United_States", split="train")
ds_gb = load_dataset(repo_id, "Great_Britain", split="train")
ds_south_korea = load_dataset(repo_id, "South_Korea", split="train")
Practical use cases
1. Persona-based prompting
The most direct use is to condition a model on a persona and ask it to generate an answer, conversation, story, or opinionated response from that perspective.
persona = ds_morocco[0]["persona"]
prompt = f"""
You are writing a short first-person answer grounded in this persona.
Do not repeat the persona verbatim. Reflect the values and background implicitly.
Persona:
{persona}
Question:
What makes a community trustworthy?
"""
This is useful when building culturally varied synthetic data, simulated user populations, or controlled evaluation prompts. The important constraint is that the persona should guide generation without being treated as a real person’s complete biography.
2. Retrieval for culturally grounded generation
Because each persona is plain text, it can be embedded and retrieved. A researcher can retrieve personas relevant to a topic such as trust in institutions, migration, work values, political participation, or family norms, then use those profiles as conditioning context.
This is often cleaner than sampling random country labels. Retrieval lets the data pipeline select profiles that actually mention the theme under study.
3. Value-sensitive model evaluation
WVS2Persona can help create evaluation sets for questions where cultural and social values shape the answer. For example, researchers can sample personas from a country subset, ask a model to answer a question under each profile, and then compare answer patterns across countries, demographic groups, or value dimensions.
This does not replace statistical analysis of the original WVS data. It gives LLM researchers a text-native layer for testing how models behave when values are explicit in the prompt.
4. Summarization and compression research
The full persona descriptions are long. That makes the dataset useful for studying controlled summarization: how to compress a survey-grounded profile into a shorter prompt while preserving the value signals that matter for downstream generation.
That direction connects back to NileChat, where compact personas were used inside controlled synthetic data generation prompts.[1]
Good practices
Use WVS2Persona as a research and prototyping resource for culture-aware AI, not as a source of stereotypes. A persona is a textual rendering of one respondent’s survey answers. It should not be generalized to an entire country, religion, gender, class, or language community.
For most experiments, I recommend reporting:
- which country subsets were used,
- how personas were sampled,
- whether full personas or compressed summaries were used,
- what prompt template conditioned the model,
- how sensitive attributes were handled,
- and whether outputs were evaluated at the individual-profile level or aggregated level.
This documentation is not busywork. It is what makes persona-based cultural alignment experiments reproducible and less likely to turn into anecdotal claims.
FAQ
What is WVS2Persona?
WVS2Persona is a dataset that converts World Values Survey Wave 7 respondent records into English textual personas. Each row contains a stable persona_id and a full persona description grounded in decoded survey answers.[2]
How many personas are included?
The current release contains 97,220 personas across 66 country subsets.[2]
Is WVS2Persona synthetic data?
It is not synthetic in the sense of inventing people from scratch. Each persona is a deterministic natural-language rendering of one WVS respondent record. However, the text is generated from decoded survey responses, so it is not a verbatim respondent statement.[2]
How is it connected to NileChat?
The dataset follows the WVS-to-persona construction approach introduced in NileChat. NileChat used WVS-derived personas as part of controlled synthetic data generation for culturally aware LLM adaptation.[1]
What can I build with it?
Common uses include persona-based prompting, culture-aware synthetic data generation, retrieval over social profiles, value-sensitive model evaluation, and summarization of long persona descriptions into compact prompt-ready profiles.
What should I avoid?
Avoid treating a persona as a full biography or as representative of an entire group. Avoid using individual personas to make claims about countries or communities without aggregation, sampling documentation, and careful interpretation.
Summary
WVS2Persona is useful because it makes cultural values operational for LLM workflows. It does not reduce culture to a country tag. Instead, it gives researchers a large set of respondent-level textual profiles that can be sampled, retrieved, summarized, and used as conditioning context.
The broader lesson from NileChat still applies: culturally aware AI needs language, local knowledge, and values to be modeled deliberately. WVS2Persona focuses on the values part of that pipeline and makes it easier to reuse across communities.
References
- El Mekki, A., Atou, H., Nacar, O., Shehata, S., and Abdul-Mageed, M. (2025). NileChat: Towards Linguistically Diverse and Culturally Aware LLMs for Local Communities. EMNLP 2025. ACL Anthology
- El Mekki, A. (2026). WVS2Persona: Parsed World Values Survey (WVS) Wave 7 records into textual personas. Hugging Face Dataset. Dataset card
- World Values Survey Association. World Values Survey Wave 7 documentation and questionnaire resources. Documentation
Links
- Dataset: https://huggingface.co/datasets/3ebdola/wvs2persona
- Underlying WVS data-use terms: https://www.worldvaluessurvey.org/AJDownloadLicense.jsp
- NileChat paper: https://aclanthology.org/2025.emnlp-main.556/
- NileChat blog post
Disclaimer (April 25, 2026): The latest version of this blog post was post-edited and formatted using an LLM.